My local setup Worklog
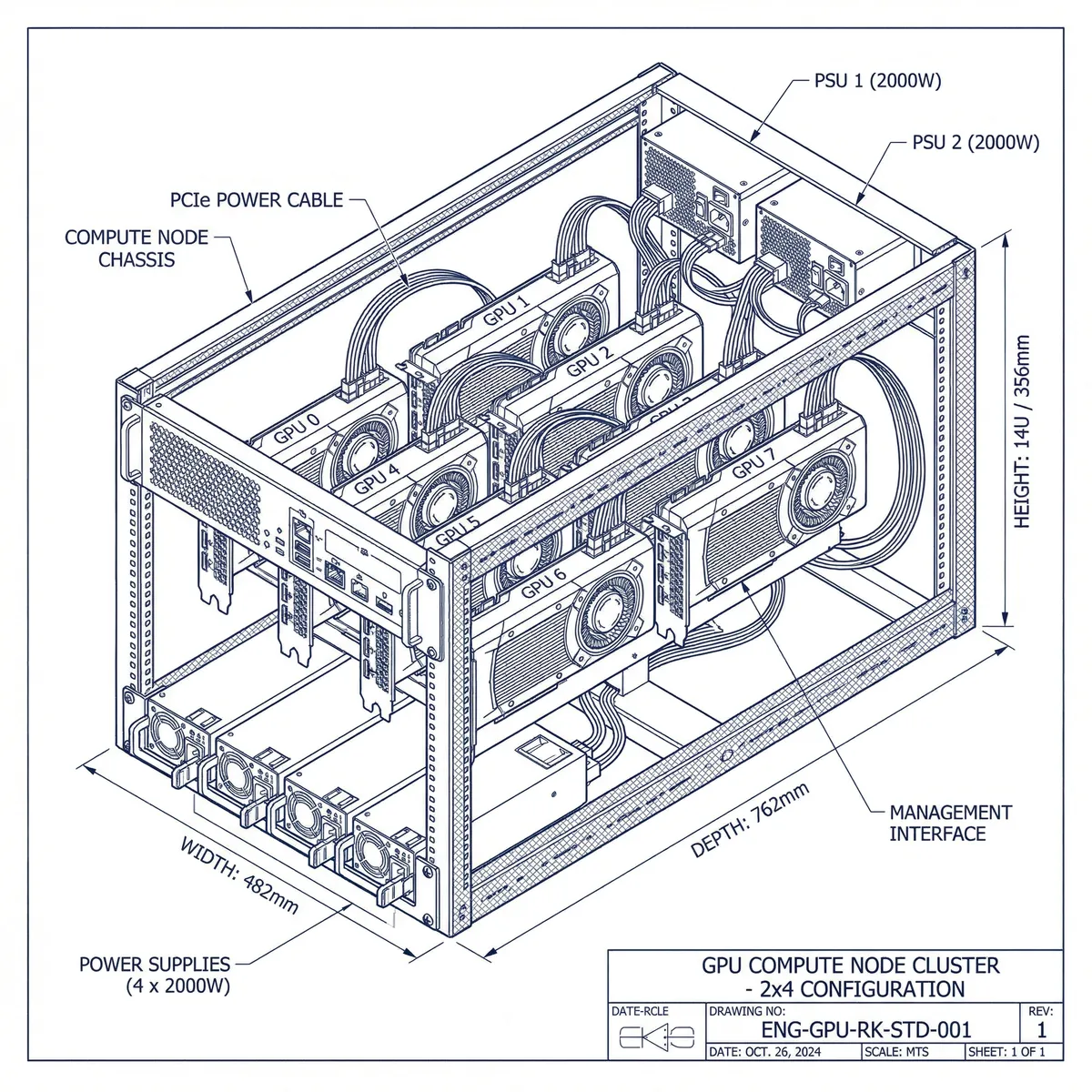
Local AI System: Sovereign ML Stack (Personal Architecture)
I'll be documenting my local AI setup as a ongoing process but here's what I have now
What I’ve built is not just a “local AI setup” in the typical sense. It is a tightly integrated system where local compute, cloud execution, and storage are deliberately separated but deeply interconnected, so that I can move from idea to large-scale execution without friction. The entire system is designed around one core principle: control stays local, execution scales externally, and state is never tied to compute.
Core Architecture
At the highest level, my system operates across three distinct but connected layers: local intelligence, cloud-scale execution, and externalized storage. These layers are not loosely connected—they are explicitly designed to interoperate through deterministic interfaces.
The local layer is where all thinking, control, and inference happens. This is my GPU rack with nine RTX 3090s, running Ubuntu LTS or Debian as a stable base. I treat this machine as a server node, not a desktop. I never run training here. Instead, I use it exclusively for inference workloads, agent execution, and system orchestration. All model serving is done through vLLM, which allows me to efficiently handle large models with paged attention and proper KV cache management. The system is intentionally not run at full capacity. I maintain roughly 70–80% utilization, which gives me enough headroom for KV cache expansion, agent execution, and long-running inference stability. Running at 100% would increase crashes, memory pressure, and degrade system reliability over time, so I explicitly avoid that.
On top of the inference layer, I run a local MCP server, which acts as my internal knowledge system. This is not just a document store. It’s a structured, indexed system backed by a vector database where I store embeddings, research notes, system documentation, and internal artifacts. This allows my agents to operate with context and memory rather than stateless prompting. The MCP server integrates with my private repositories and local data through controlled authentication, so the entire intelligence layer remains private and self-contained. To support persistence and scalability, I extend this with a NAS, which stores embeddings, structured knowledge, and long-term datasets. The NAS is not used for high-throughput training data but for everything I want to keep local, durable, and accessible to my agents and inference stack.
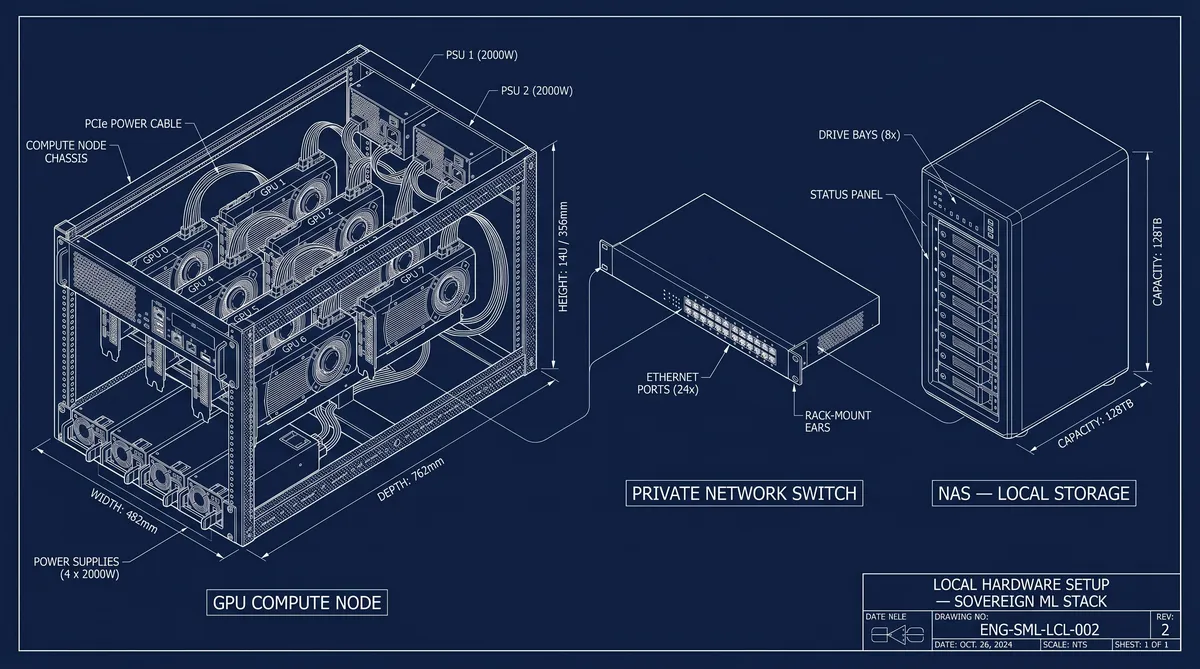
Cloud Execution and Training
The cloud layer is where actual heavy computation happens, but I treat it as stateless and disposable. When I need to train models at scale, I provision machines on demand—H100s, RTX Pro 6000s, or similar hardware. These machines start as bare metal or minimal OS images. I do not rely on pre-configured environments. Instead, everything is bootstrapped through my own system.
Once provisioned, the machine is accessed through SSH, usually triggered by an agent. From there, a Docker image is executed, which builds the environment deterministically. These images are not generic. Each one is project-specific and architecture-specific, containing only the dependencies required for that exact run. For example, if I’m running a transformer model on SM90 architecture, I only compile the relevant FlashAttention kernel for that architecture using Ninja. I do not include kernels for other architectures because that would introduce unnecessary overhead and instability. The resulting image is around 10GB, which is extremely lean compared to typical ML environments.
I never clone my full repository into these machines. Instead, I copy only the required slice of the codebase, such as the training module, infrastructure bindings, and execution scripts. This keeps execution minimal and reduces the chance of failure. Once inside the container, I use tmux sessions to orchestrate runs, allowing me to manage multiple experiments, ablations, or distributed training jobs concurrently.
Data and Storage Flow
All heavy data is externalized. I do not store datasets, checkpoints, or logs on compute nodes. Instead, everything lives in cloud object storage, organized into project-specific buckets. I use rclone to stream data directly into training pipelines. This allows me to treat compute nodes as completely ephemeral. I can spin up a machine, run a job, and destroy it without worrying about persistence.
This separation is critical. It ensures that:
- the repository remains clean and deterministic
- compute remains stateless and reproducible
- storage becomes the single source of truth
The NAS complements this by holding private data and knowledge locally. So the system ends up with a hybrid model: cloud for bulk training data, local for knowledge and intelligence.
Networking and Isolation
All components are connected through a private network layer using Tailscale (WireGuard). This allows secure access without exposing any machine to the public internet. Even though the systems are physically on a home network, they behave as isolated nodes in a controlled environment. SSH access, agent execution, and orchestration all happen through this private overlay.
From a systems perspective, this effectively turns the entire setup into a private distributed system spanning local and cloud environments.
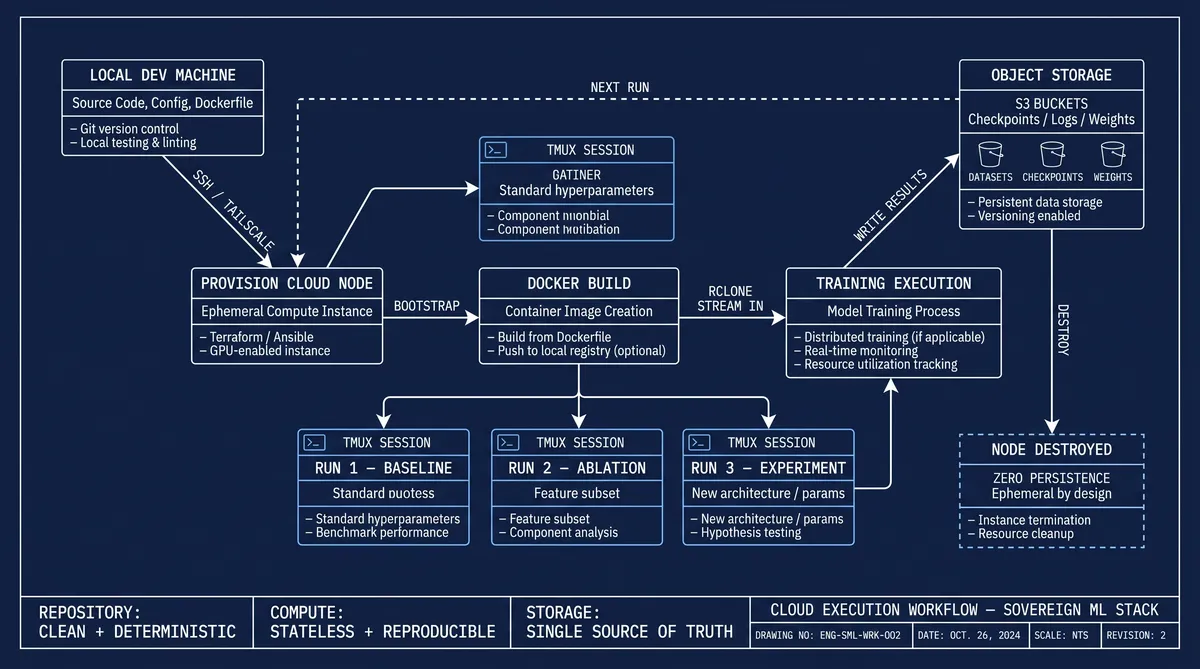
Execution Flow
The integration of all these components creates a consistent workflow. Code is developed and validated locally within a clean monorepo that contains only logic and configuration, never large artifacts. Once verified, only the necessary components are transferred into a cloud execution environment. The Docker container rebuilds the exact runtime, data is streamed in via rclone, and training executes at scale. Results are written back to object storage, and the compute node can be destroyed without loss.
Meanwhile, the local system continues running inference, agents, and orchestration independently. Because operations are automated, I do not manually provision machines or configure environments. The agent handles infrastructure, and I focus only on defining objectives, architecture, and constraints.
Design Philosophy
The system is built on a strict separation of concerns:
- Local system = control, inference, and memory
- Cloud system = training and large-scale execution
- Storage = persistent state, fully decoupled from compute
This architecture avoids the common pitfalls of ML systems, where code, data, and compute are tightly coupled. By separating them, the system remains stable, scalable, and easy to reason about.
Closing Perspective
This setup eliminates almost all infrastructure friction. Environment setup, dependency management, and scaling concerns are effectively solved. Everything is deterministic, reproducible, and under my control.
At that point, the system is no longer about how to run models or manage infrastructure. It becomes something else entirely:
the limiting factor is no longer compute or engineering—it is the choice of what to build next.